
AI Grading Assistant
Secondary Research | Primary Research | Re-define the problem | Ideation | Wireframes & Prototyping | Testing & Iterating | Wrapping Up
Getting Started
An artificial intelligence / machine learning (AI/ML) research and development team had a number of design challenges with a first generation AI prototype. I was brought on the team to help solve these problems. Utilizing my background in UX, statistics, and psychology, I helped solve a number of new design challenges associated with human-AI interaction and collaboration in the grading of higher education student writing.
Indirect team members, remote
-
UI/UX designer
-
UX researcher
-
Learning designer & researcher
-
Product marketing manager
-
Product manager
Direct team members, in-person
-
Senior Data Scientist - ML Engineer
-
Senior Data Scientist - ML Engineer
-
Senior Data Scientist - ML Engineer
-
Senior Research Engineer - Front-end Developer
-
Senior Research Engineer - Back-end Developer
-
Principal Data Scientist - ML Modeling
-
Principal Data Scientist - ML Modeling
-
Senior Research Scientist - ML Modeling
-
VP AI Products & Solutions (Background: Cognitive Psychology & Computer Science)
Company
Pearson
Duration
9 months
Role on Project
AI researcher & designer
Skills Demonstrated
Quant & qual Research
Product management & strategy
Wireframing
Prototyping
Concept testing
Usability testing
The team initially approached AI products as APIs that could be used to incorporate AI technology into other internal and external products. However, the team quickly realized that some AI products could be APIs, while with others the product design and UX of AI made the technology sink or swim. In other words, UX and human-AI interaction has a direct impact on ML model performance. This meant that UX needed to be researched and designed upfront working hand-in-hand with the AI team, rather than relying on external groups to design the interaction with the use of an API.
After interviewing and discussing issues with team members and stakeholders, there were a number of challenges and individual assumptions brought to the table.
1
1
Balancing legacy grading flows with flows that are best suited for training an AI (i.e., intelligent ordering / active learning)
2
2
Cultivating trust in AI
3
3
Communicating progress and human-to-AI handoff
4
4
Removing grader bias in ML models
1. Balancing legacy grading flows with flows that are best suited for training an AI
I was told instructors are highly opinionated about their grading workflows. These grading workflows may involve the following:
-
Starting to grade with familiar students
-
Making multiple passes and adjusting scores along the way
-
Delegating to TAs, adjudicate as necessary
-
Identifying anchor papers and grading relative to exemplars
AI takes a different approach to the above assumed instructor grading workflows and it involves an ML technique called active learning. The aim of active learning is to reduce human grading effort required to train an AI by prioritizing which student submissions should be graded first. For instance, the AI will grab submissions that are most different from each other and which best represent the total student submission pool to be graded by the human first. Ideally, humans would follow the AI’s suggested grading order since divergence from the order would lead to suboptimal AI training and require more time spent grading.

The original design had a suggested order; however, instructors could click any name to begin grading. Instructions on grading order were subtle and could be easily missed or not understood.
2. Cultivating trust in AI
Many instructors are inherently skeptical of AI. To overcome this, in initial designs the following design principles were followed:
-
AI grades are communicated as guidance, not as a definitive outcome
-
AI grades are not surfaced out-of-the-box
-
Discrepancies in grading are surfaced, but model performance is not overtly shown
-
Human graders can always override AI grades

In the original design an instructor manually grades until the training progress bar turns green.

In the original design, after the AI was able to automatically populate grades, the instructor could always override the AI grades.
3. Communicating progress and human-to-AI handoff
Those versed in ML and psychometrics use statistics like inter-rater reliability, percent agreement, and/or correlation to determine when a model is “good enough”. However, exposing these statistics to lay-people complicates the interface and introduces doubt and uncertainty in AI capabilities. The challenge here centers around determining which proxies can be communicated so non-technical instructors are able to make decisions on when it’s safe to hand-off grading to an AI assistant.


Original designs, communicating progress and hand-off
Original designs, communicating progress and hand-off
4. Removing grader bias in ML models
Ideally, grading happens blindly without identifiable student information. In reality, instructors have access to names, and while this may add bias to grading, it may also help with giving a quality check on AI assistant grading.
These four challenges contained many individual and team assumptions. One of my first design research goals was determining the extent to which these challenges and assumptions were correct and to determine what designs could overcome these challenges. To start, I jumped into secondary research.
I conducted secondary research in order to get more knowledge, context, history, and data surrounding the design challenges at hand. I started by diving into the research and practice of AI essay grading, supervised learning and active learning, and human-AI interaction.
AI Essay Grading
Machine Learning was in existence long before the current AI/ML boom. My manager, who now leads the team responsible for AI and Natural Language Processing (NLP), began automated essay grading in 1994 in his large psychology courses at The University of Colorado Boulder and in 1998 he formed Knowledge Analysis Technologies. In 2004 Pearson acquired Knowledge Analysis Technologies and the group was renamed to Pearson Knowledge Technologies (PKT).
The technology that PKT uses incorporates an automated, mathematical way of representing and assessing the content of text that corresponded to judgments that people make about the similarity in meaning between passages of text and individual words. This technology is based on Latent Semantic Analysis (LSA), a machine learning technique that acquires and represents knowledge about the meaning of words and documents by analyzing large bodies of natural text (e.g., a sample of texts that is equivalent to the reading a student is likely to have done over their academic career, approximately 12 million words). Along with LSA content-based measures, a range of other measures are also used to assess lexical sophistication, grammar, mechanics, style, and organization of writing.


Additionally, with PKT, an ML technique is used to learn how to grade based on trained human graders. AI training involves collecting a representative sample of writing assignments that have been graded by humans. At least two human graders are used to get an estimate of reliability by having them grade 200-300 writing assignments. This is done to get a level of agreement between the two human graders and to get an estimated “true score” for each writing assignment. The 200-300 graded essays is the typical amount needed to train an ML model (note: this is referred to as “labeling the data” in ML). The AI technology extracts features from the essays that measure aspects of performance. Then the AI examines the relationship between the human grades and the extracted features in order to learn how the human scorers weigh and combine the different features to produce a grade. This results in an ML grading model which can be used to grade new writing immediately. Additionally, utilizing the model, the AI can first analyze submissions to determine the confidence with which it can grade them accurately; for instance, identify off-topic, non-English, highly unusual, or creative writing which can be directed to a human for grading.
The performance of a scoring model can be evaluated by examining the agreement of the machine’s predicted grades to human graders, as compared to the agreement between human graders (noting that the “true grade” for an essay is the average of multiple human grades). Reliability metrics include correlation, kappa, weighted kappa, exact agreement, and adjacent agreement. An example statistic to evaluate model performance is typically a machine-human correlation of roughly .7 or above; or in other cases within 10% of human-human agreement. Noting that, in psychology and psychometrics, these benchmarks are approximately the same statistics one looks for good reliability between humans.
Pearson has a set of writing assignment prompts that have been trained with expert human graders using a method similar to what is described above. It can take up to 18 months and $10,000 to get the labeled data (i.e., human grades) and build ML models that can automatically grade student writing for one writing prompt. Clearly expensive. One of the goals of this AI product was to increase the efficiency of writing prompt development by having the instructor provide the labeled data (i.e., grade) while having an ML model learn to grade from the instructor on the fly.
Supervised Learning & Active Learning
There are a number of different ML techniques, including: supervised learning, unsupervised learning, deep learning, and reinforcement learning. As discussed in the previous section, the AI assistant is trained by having humans grade writing assignments. In ML this falls under a supervised learning approach, and in the current project was framed as a logistic regression problem.
Active Learning is a field of ML concerned with reducing the amount of labeled data needed to train a supervised model. In particular, active learning uses an algorithm to intelligently order the writing assignments to be graded first; for instance, by selecting the most divergent essays (i.e., essays that best represent the total group of student submissions) to be graded by the human first. By selecting the essays that are most relevant to model training, this approach substantially reduces the human grading workload. As stated earlier, typically it takes about 300 graded writing assignments to train a ML model, with active learning this number can be dramatically decreased. With active learning, a small subset of essays are selected for grading. After that subset is graded by a human, a model is built and evaluated. If the model meets performance criteria (e.g., .7 or higher Pearson correlation coefficient of the model predictions and the average human score), the remainder of the essays can be automatically graded.

Active learning clashes with the earlier stated assumption that instructors like to choose the order in which they grade. This is a case of AI wants and needs directly clashing with human wants and needs. But what if humans knew the trade-off? If given a choice between having control over grading order and saving time, which is more important? How many instructors actually prefer to grade in an order? And even if humans have an order preference, how much bias creeps in which the AI will learn?
This all comes back to user goals. The AI’s goal is to train a satisfactory model while having the human grade/label the data with as few essays as possible. Is the human’s goal to save time and grade fairly (i.e., without bias)? In this case, the order should default to the AI’s preference.
Human-AI Interaction
AI technology can violate established usability guidelines of traditional user interface design. Because of this, a set of 18 design guidelines for AI-human interaction have been developed by a few different groups/organizations. AI technologies are often performed under uncertainty, producing false positives and negatives. Additionally, AI technologies may demonstrate unpredictable behaviors that can be disruptive, confusing, offensive, and even dangerous. However, many AI components are inherently inconsistent due to poorly understood, probabilistic behaviors based on nuances of tasks and settings, and because they change via learning over time. The authors of the design guidelines wanted to further investigate how designers and ML model developers can work together to effectively apply the guidelines. For example, given the expected performance of an ML model, designers may recommend specific designs that reduce costs while optimizing benefits to users.


Next, I dove into human-AI interaction by zooming out and looking at parallels between, a) human-human interaction, b) human-computer interaction, and c) human-AI interaction. I see human-AI interaction as sitting somewhere in between human-human interaction and human-computer interaction, leaning much closer to human-computer interaction, afterall AI can be considered a “machine”. That being said, there is a big difference in that AI is designed to learn from and mimic human judgment, decision making, and behavior, while static computers and websites are not.
human-AI interaction also varies drastically depending on the task and context. In this product the AI and humans needed to collaboratively work together to achieve the best result (i.e., saving time and grading accurately). In this situation, the instructors bring many preconceived notions and folk-theories about AI to the table. For instance, some assume that an AI can learn to grade exactly like them. This is a misconception. Afterall, a human can’t even agree with themselves 100% of the time (otherwise known as intra-rater reliability). In psychometrics/statistical terms your correlation with an AI can only be as high as you correlate with yourself. For example, you grade a set of writing, set it aside, a month later come back and grade it again. The correlation between your time 1 scores and your time 2 scores is your intra-rater reliability. Let’s say this correlation is .85 (pretty good!). This number sets the upper limits of how high an AI can correlate with you. In other words, .85 is the highest correlation you could have with an AI in this situation, a 100% agreement with AI is NOT possible and a correlation of .85 is highly improbable. In other words, the quality and reliability of the human grades will affect the AI’s ability to learn from human.
Additionally, a common request from people is that they want AI to be explainable. Or rather, they want an exact explanation of how the AI arrived at its judgments and decisions. A nearly impossible task. When instructors are told an exact explanation can’t be given, their reaction is to lower their trust in AI. The ironic aspect of this is that if you asked an instructor how they arrived at a grade, they could give an explanation, however, the explanation is likely incorrect. Humans do not have access to all of the why’s and how’s of what influences their decision making. They will attempt to give a rational explanation,
“Well, Amy’s organization of the paper made it hard to follow resulting in her overall lower grade.”
This could be (and likely is) a completely inaccurate explanation for how the instructor actually arrived at the grade, which is influenced by a host of factors outside of the instructor’s awareness. For example, the writing may have triggered a negative memory which unfairly affected the grade the student was given. Or the grade may have been the result of a general order effect, for instance choosing to grade ‘the best’ students first. In general there are conscious and nonconscious, or rather explicit and implicit, influences to human judgment and decision making which make human decision making very hard to explain - just like humans’ AI counterparts.
Additionally, humans don’t know what they don’t know, and this places additional limits on traditional UX research when AI interaction is involved. A traditional user interview to gather user wants and needs would result in a different outcome if the human understood the wants and needs of the AI. For example, an instructor may have the want/need of grading in an order, but explaining how if they are given this option how it will increase their time spent grading and decrease the accuracy and AI performance is not exactly an easy and straightforward task in a user interface. In the end, the human has wants/needs/goals and the AI has wants/needs/goals and both must be taken into consideration when making design decisions and the design must bridge the communication gap between the two.
"If the goals of an AI system are opaque, and the user's understanding of their role in calibrating that system are unclear, they will develop a mental model that suits their folk theories about AI, and their trust will be affected."
-Josh Lovejoy, People + AI Research, Google
https://design.google/library/ux-ai/
Secondary Research
A series of three pilots were conducted with the version 1 AI tool. Pilots utilized qualitative and quantitative research methods. In addition, heuristic evaluations and experiments were conducted.
The Initial Pilot
The first pilot was conducted with an Introduction to Psychology course at a large Midwestern university. Users were 1 lead professor, 8 TAs, and 884 students who responded to 3 writing assignments/prompts. The pilot contained the following 3 conditions.
-
Human & AI grading: Not using active learning (i.e., the human selects submissions to grade)
-
Human & AI grading: Active learning provides essays to score for the first 10 or first 20 essays (i.e., AI selects submissions to grade)
-
All human grading
Qualitative. Post-pilot, a series of user interviews were conducted with the TAs. The interviews were conducted by Pearson's Learning Design team and I reviewed all coded all interviews for themes and reported out results.
Quantitative. Data from the pilot were analyzed, some key statistics were as follows:
-
Percent of essays human graded: 23%
-
Percent of essays AI graded: 73%
-
Percent of essays where the human changed the AI's grades: 4%
-
On average, humans would only revise approximately 1.7 AI grades, very low given agreement statistics as follows:
-
Instructor-AI: .363
-
TA-AI: .312
-
TA-TA: .173
-
Instructor-TA: .240
-
note: Reliability of human grading and correction for attenuation
-
Note: Lower correlations due to range restriction (90% of all student scores were 3's or 4's )
-
-
Average time human's spent grading an essay was 1 2/3 minutes, meaning the humans were not closely reading and grading the students' essays
Overall, the quantitative analyses let to more questions than answers and unfortunately, the interviews took place prior to the data analyses. Additional questions I would have asked and assessed were:
-
How closely did they grade?
-
How motivated were they?
-
Were they grading according to the rubric or just skewing grades to be higher for completion scores?
-
They reported that AI was very accurate however agreement statistics suggested otherwise, why?
Subsequent Fall & Spring Pilots
The second and third pilots were conducted with a sample of universities and instructors throughout the United States over the Fall and Spring terms. In the Spring pilot 98 instructors and over 1,000 students participated in 5 different research tracks.
Qualitative & Quantitative. Post-pilot interviews were conducted with a sample of participating instructors and students. Post-pilot surveys were sent to all participating instructors and their students.


Heuristic Evaluation &
Experiments Utilizing Pilot Data
Heuristic evaluations/cognitive walkthroughs were conducted with the AI engineering team to assess the human-AI interaction design clarity and feasibility. Further, in an effort to examine the effect of a human choosing the grading order (and settle the debate between the ML engineers and the UI/UX designer who designed version 1 of the AI tool) I asked for an active learning experiment comparing model performance of different active learning algorithms. To simulate an instructor choosing a grading order, sorting based on essay length was chosen. This order would best represent a human selecting the best essays/students to grade first. This algorithm was compared against random and the standard active learning algorithms. The graph to the right shows the effects of a human choosing a grading order (see: sorted) versus the AI choosing a grading order (see: random). Results illustrate lower model performance when the human chooses the grading order.
.png)
The effects of a human choosing a grading order (i.e., represented as sorted) versus the aI choosing a grading order (i.e., represented as random). Model performance is worse when the human is allowed to choose the grading order.
All of this research, now what? Improve the design
Primary Research
Using the results from our research, I developed a problem statement. The purpose of the problem statement was to get everyone on the same page as to the problem to solve moving forward. By now it was clear that we needed to focus our attention on improving collaboration between the Human and the AI in the grading of student writing.
Human-AI design principles discussed earlier were used to help expand on our problem statement and to help guide our design decisions moving forward. Additionally, to overcome some of the limitations of traditional user-centered design the AI was defined as a user. In an effort to bring our AI to life, an AI persona was developed based on interviews with AI machine learning engineers. The AI persona was defined in a similar manner to how we define human personas, in terms of motivations, frustrations, needs, and goals.
Instructors and the AI need a way to improve collaborative decision making so that both can efficiently and accurately grade student writing.

Re-define the Problem
Design brainstorming began by looking at different animated progress bars / indicators / trackers. Visibility of system status has been one of the most important principles in UI and interaction design. Feedback on what is happening during a process is important for users; for instance, check-out process, form completion progress, onboarding process steps, or indicators for processing/wait time. Users want to know and understand their context and progress at any given second and they want to feel in control.
UX designers of system status for AI systems seem to have taken a contrary approach to this traditional UI design principle. Hiding AI system status from the user is a common approach. While other designers hold onto the traditional view of communicating the AI status/progress to the user. Obviously, the design direction should depend on the product and should be validated with user research. For the current product, the main problem to be solved was to improve human-AI collaborative decision making, meaning communicating AI system status was one big key to success.
Good interaction design provides feedback
Feedback answers the following 3 items:
Current Status: What's happening?
Outcomes: What just happened?
Future Status: What will happen next?
Good progress indicators reduce uncertainty
A good progress tracker/indicator will inform users about the following:
- What steps/tasks the user has completed
- What step the user is on
- How many steps are left
Additional brainstorming centered around information architecture, and navigation within the tool. There were many rounds of design, feedback, and expert review before arriving at the design that would be tested with users.




Ideation
Wireframes & Prototyping
Wireframing
Using the current product designs, research, and brainstorming sketches as a starting point, I wireframed an updated product design using Sketch. The original designs are shown on the left and the updated designs on the right. I took the wireframes and made a prototype using Sketch's prototyping feature.

2
1
3
1. There was no home page in the original design. The redesign included a home page to help orient the users.
2. Navigation in the original design was confusing and it was easy to get lost in the product. In the redesign, navigation from and back to the home page was more intuitive.
3. Information Architecture of courses, assignments, and grading in the original design needed to be improved. In the redesign, courses were placed in cards which contained the assignments and grading progress and actions.

1
2
3

1

3
4
2
5

2
3
4
5
1
1. Dropped the ability to choose the grading order. Instead, users are put directly into a pre-determined grading flow.
2. The AI training progress bar was redesigned and an additional step was added to help guide the user.
3. The text box was redesigned to help with readability.
4. Navigation was updated to be more intuitive and to have the buttons communicate steps the user should take.
5. Grading form was redesigned.

1
2
3

1
2
3
1. AI Training progress was redesigned to provide more information and help the user understand where they were in the grading progress.
2. The grading form was redesigned to have the grading rubric open in another window.
3. Navigation was updated to be more intuitive and to have the buttons communicate steps the user should take.

1
2
2
1. In the original design AI training ends, when in reality the human and the AI need to work together a bit longer to ensure that the AI's grading acceptable to the human. In the redesign, an additional tuning step is added to help the human spot check the AI's predictions after it has been trained to grade.
2. The human continues to grade and the navigation button communicates what will happen next in the process (i.e., the human's grades will be compared to how the AI would have graded the essay).
3. The human can see how the AI's grading differed from their grading. During this process the human continues to train the AI.
4. When an acceptable level of agreement has been reached between the human and the AI, the human can choose to keep fine-tuning the AI or finishing tuning the AI and review all of their students' grades.

1
2
1. In the original design, after the AI training was complete the human would go to a grading summary page to review grades and evaluate the AI's grading performance. This page placed a huge cognitive load on the human. In the redesign, this "review all grades" step was included in the progress bar and the content of the page was simplified.
2. The human can click into the essays that the AI assistant graded.
3. The human can select any student to review.
4. After selecting a student to review the human is taken to the student's essay and the grading form populated with the grades the AI assistant gave the essay.
5. he human can change the AI assistant's grades at any point and can quickly click through other student's grades or return to the grading summary page to finalize/submit all grades.

1

1

2

3

4

2
1

3

4

5

1
1. In the original design after the human finalizes/submits grades needed some simplification. In the redesign the AI training bar is greyed-out, yet still visible and the human can more easily see statists and grades in a glance.
Prototyping
Next, I took the wireframes and made a prototype using Sketch's prototyping feature for user testing.
Prototype
Interact with the design produced in Sketch
User Testing
To evaluate the redesign I pulled together a test plan and script, moderated user testing with 6 users, and complied user testing insights to inform design changes.
_p.png)
Iterating on the Design
I used the results from the user testing, further heuristic evaluations, and additional results from pilot data to update the design. Below a user flow of training an AI grading assistant is shown.

1
2
AI assisted grading home
1. Simplified navigation
2. Simplified actions within a course

1
Start training AI grading assistant
1. Provided just in time instructions and information on training the AI grading assistant

1
2
3
4
5
Start training AI grading assistant
1. AI training progress bar was slightly redesigned to work with the new navigation
2. Slight updates to messaging in the AI training progress bar
3. Instructions to nudge the instructors to use the full range of the scale when grading
4. Removing the overall grade in the training phase to help the instructor focus on the trait scores
5. Redesign student essay to look more like a paper
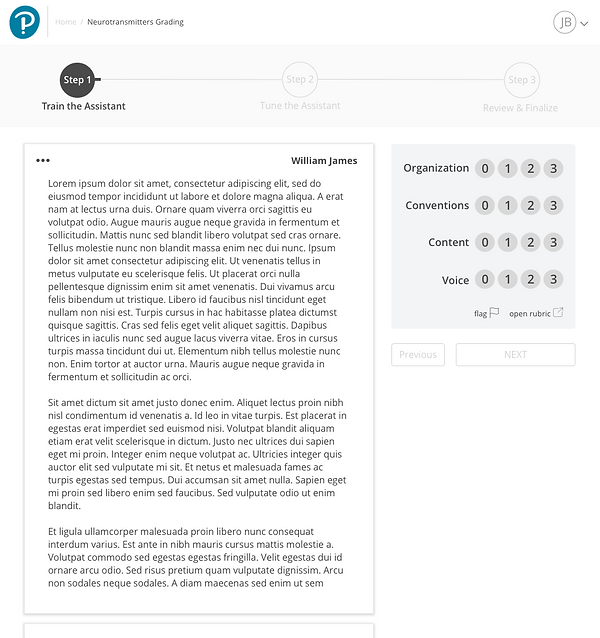
1
2
Grade the first piece of student writing
1. Simplified actions
2. Navigation helps communicate actions the user should take

1
2
Grade the first piece of student writing
1. AI training progresses as the instructor grades
2. Navigation helps communicates actions the user should take

1
2
3
Continue grading student writing
1. AI training progresses as the instructor grades
2. Navigation helps communicates actions the user should take - now the user can move forward or backward in their grading order
3. Added commenting feature

1
2
3
AI training is complete, now it's time to tune the AI grading assistant
1. The AI training progress bar communicates the training is complete and the user has moved to the tuning phase
2. UX Copy communicates what is happening to the user
3. Navigation helps communicate actions the user can take

1
The user continues grading
1. After grading a student's piece of writing the navigation communicates what will happen next, in the tuning phase the instructor's grades will be compared to how the AI grading assistant would have graded the writing

1
1
The user compares their grading to how the AI assistant would have graded
1. The user sees any disagreements between them and the AI. This provides additional information to the user on how much more training the AI needs

1
The user continues grading and tuning the AI assistant
1. Navigation helps communicate actions the user can take
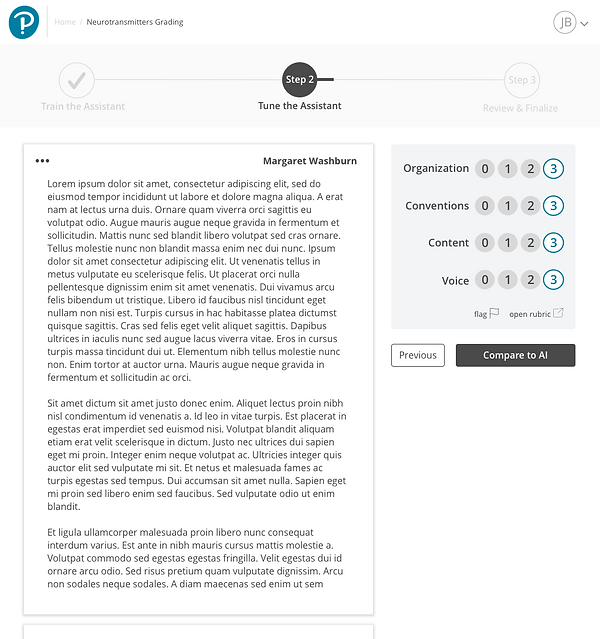
1
The user continues grading and tuning the AI assistant
1. Navigations helps communicate what will happen next and actions the user can take

1
2
3
The user compares their grading to how the AI assistant would have graded
1. The user sees any disagreements between them and the AI. This provides additional information to the user on how much more training the AI needs
2. The AI training progress bar helps communicate how well the AI grading assistant is performing
3. Navigation helps communicate actions the user can and should take - they should review all grades; however, they can continue training the AI assistant

1
2
After the user selects "review all grades" they are brought to the grading summary page where they review and finalize grades
1. The AI training progress bar communicates were the user is in the process and what they need to do next
2. The user can easily find and review writing that was graded by the AI assistant

1
Review writing that was graded by the AI assistant
1. The user can click on a student to review their writing

1
2
Review writing that was graded by the AI assistant
1. The user reviews trait scores given by the AI assistant
2. Navigation communicates actions the user can and should take

1
Adjust AI assistant grades
1. The user can always override any AI assistant grades

1
Return to the grading summary page, and submit grades
1. When the user has completed reviewing grades they can submit grades at anytime

1
2
Grades have been finalized
1. Grades have been finalized; however, the user can go back in and make any adjustments as necessary
2. The AI has been trained to grade this assignment and the instructor can use it to automatically grade student submissions
Publications & Patents
This project resulted in two publications and five patents.

Baikadi, A., Becker, L., Budden, J. S., Foltz, P., Gorman, A., Hellman, S., Murray, W., Rosenstein, M. (2019). An Apprenticeship Model for Human and AI Collaborative Essay Grading. Association for Computing Machinery, Intelligent User Interfaces (ACM IUI) Workshop (March 2019).

Hellman, S., Rosenstein, M., Gorman, A., Murray, W., Becker, L., Baikadi, A., Budden, J., & Foltz, P. (2019). Scaling Up Writing in the Curriculum: Batch Mode Active Learning for Automated Essay Scoring. Association for Computing Machinery, Learning @ Scale (June 2019).
Patent 1
Systems and methods for interface-based machine learning model output customization
P2550-US-5
Patent 1
Patent 2
Systems and methods for automated machine learning model training quality control
P2550-US-3
Patent 2
Patent 3
Systems and methods for automated evaluation model customization
P2550-US-1
Patent 3
1
2
3
4
5
Systems and methods for automated machine learning model training quality control (Jan 2024, Patent #11875706)
Systems and methods for interface-based automated custom authored prompt evaluation (Nov 2023, Patent #11817014)
Systems and methods of interface-based machine learning model output customization (Aug 2023, Patent #11741849)
Systems and methods for automated evaluation model customization (Oct 2022, Patent #11475245)
Real time development of auto scoring essay models for custom created prompts (Sept 2022, Patent #11449762)